Empresas Premium








Un equipo de investigadores del Departamento de Lenguajes y Sistemas Informáticos de la ETSI Informática de la UNED, en colaboración con especialistas en salud pública de la Consejería de Sanidad de la Comunidad de Madrid, ha desarrollado un sistema pionero de análisis de lenguaje natural capaz de identificar y clasificar 19 enfermedades raras específicas en informes clínicos redactados en español. El trabajo, titulado “Un enfoque integrado para la detección y clasificación de enfermedades raras en informes médicos pediátricos españoles”, acaba de publicarse en la revista Scientific Reports.
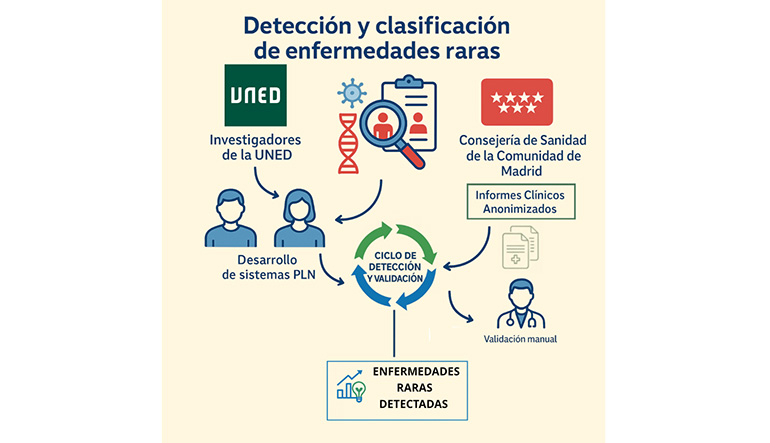
Los autores —entre ellos los profesores de la UNED Juan Martínez-Romo, Lourdes Araujo y Andrés Duque, junto a María D. Esteban-Vasallo, María-Felicitas Domínguez-Berjón y David Malillos Pérez— abordan uno de los grandes desafíos del procesamiento automatizado de información biomédica: reconocer con precisión menciones a patologías poco frecuentes en registros médicos reales, redactados sin estandarización y con la complejidad inherente al lenguaje clínico.
La investigación se ha centrado en una cohorte de datos anónimos procedentes de historias clínicas pediátricas de atención primaria en la Comunidad de Madrid. A partir de casi 250.000 notas médicas, el equipo ha desarrollado un sistema híbrido que integra técnicas lingüísticas avanzadas y modelos basados en arquitecturas Transformer, un tipo de redes neuronales que ha revolucionado el procesamiento del lenguaje natural gracias a su capacidad para analizar grandes volúmenes de texto, identificar patrones complejos y comprender el contexto de las palabras dentro de una frase con mayor precisión que los sistemas tradicionales.
El proceso automatiza una primera criba: la IA selecciona posibles menciones a enfermedades raras —desde síndromes genéticos hasta trastornos metabólicos muy poco comunes— y posteriormente expertos clínicos validan esas detecciones. Gracias a este trabajo conjunto se ha generado un archivo de 1.900 textos clínicos anotados, uno de los recursos más valiosos hasta la fecha para el estudio de estas patologías en español.
Los resultados muestran que el enfoque funciona muy bien. Los modelos más avanzados lograron identificar correctamente más del 78 % de los casos, una medida que combina precisión y capacidad de detección. Esto supone una mejora de más de diez puntos respecto a los primeros sistemas utilizados, un avance especialmente importante en un contexto donde los datos disponibles son limitados, como suele ocurrir con las enfermedades raras.
La precisión del sistema también se debe a la adaptación minuciosa al español clínico: manejo de negaciones, distinción entre enfermedades presentes y antecedentes familiares, o identificación de referencias indirectas. Todos ellos elementos clave para no confundir diagnósticos con sospechas, descartes o información heredada.

